Relevance
Newest
Oldest
Insights
-
Featured
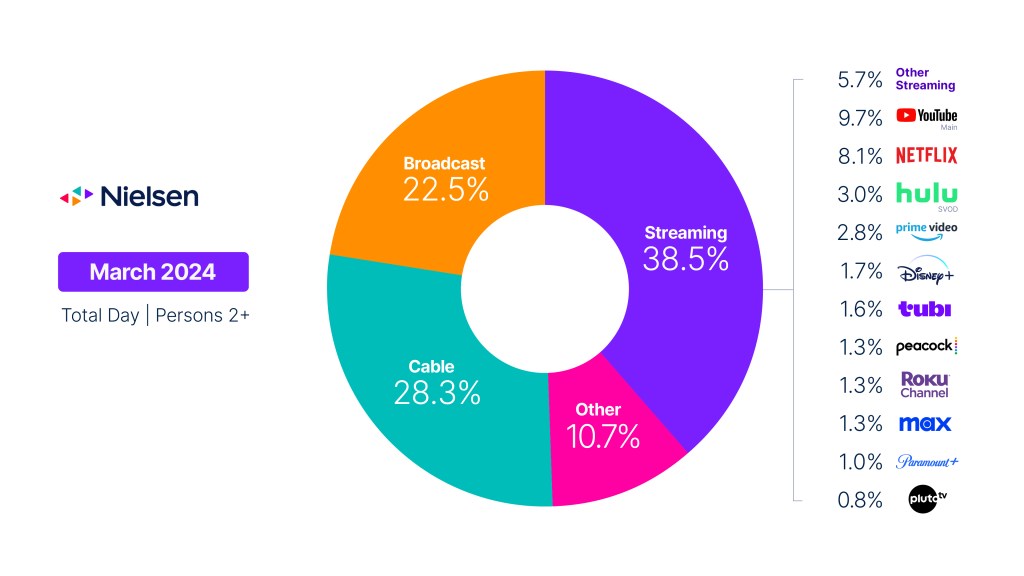
College basketball boosts U.S. cable viewing in March
Following seasonal viewing trends that typically begin in February, overall television usage in the U.S. dipped again in…
TV & streaming5m read
-
 Article
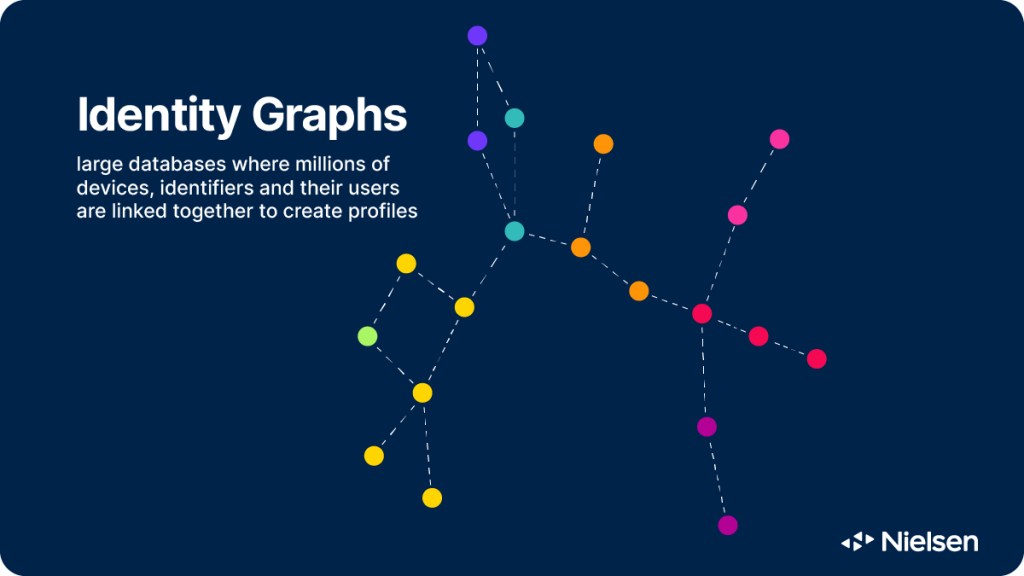
ArticleNeed to Know: What’s an identity graph and why do marketers need them?
For consistent, comprehensive and comparable audience measurement across platforms, marketers need a robust ID system…
Marketing performance7m read
-
 Article
ArticleMetadata is the key to compelling fan experiences as sports migrate to streaming
Sports, unlike all other genres, have the power to attract large, consistent TV viewership—and on set schedules….
TV & streaming4m read
-
Article
College basketball boosts U.S. cable viewing in March
Following seasonal viewing trends that typically begin in February, overall television usage in the U.S. dipped again in…
TV & streaming5m read
-
Featured
Need to Know: What’s an identity graph and why do marketers need them?
For consistent, comprehensive and comparable audience measurement across platforms, marketers need a robust ID system…
Marketing performance7m read
Featured reports
-
 Report
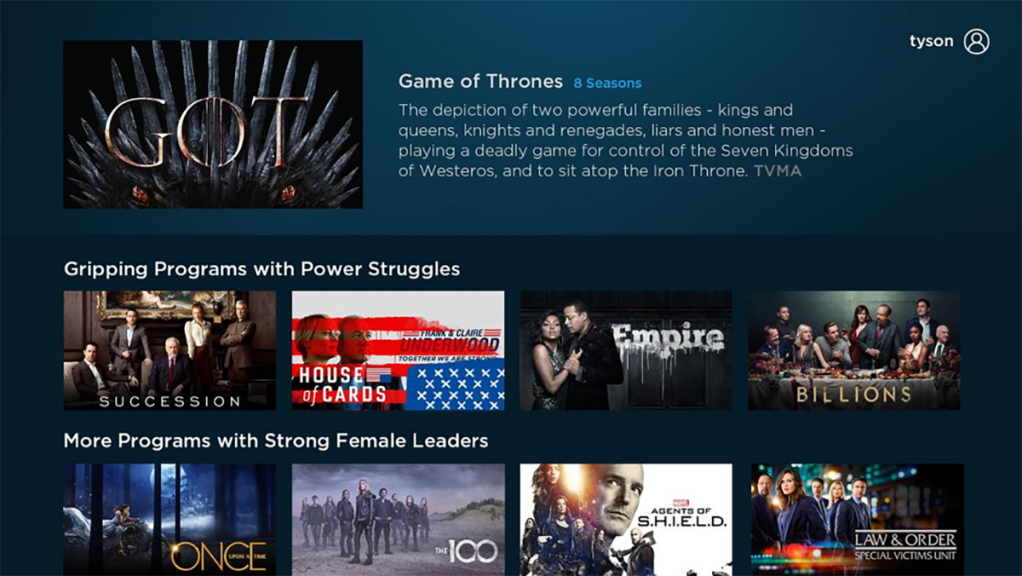
ReportMetadata matters: Powering future FAST channel success
This guide will help FAST channels prepare for the future, when search and discovery features within individual services…
TV & streaming1m read
-
 Report
ReportThe global Black audience: Shaping the future of media
Black America continues to diversify, and media will need to evolve to stay relevant for this media-hungry audience with…
Audiences5m read
-
 Report
ReportThe Upfronts/NewFronts Guide 2024
Discover the data and insights you need to navigate a shifting media landscape with Nielsen’s 2024-25 Upfronts/NewFronts…
Advertising18m read
