최근 몇 년 동안, 대규모 단일 소스 데이터 세트의 생성은 광고 연구 업계에 큰 도움이 되었습니다. 닐슨 카탈리나 솔루션에서는 수백만 가구의 매장 내 판매 데이터와 해당 가구가 특정 광고 캠페인에 노출되었는지 여부에 대한 정보를 결합하고 있습니다. 노출된 가구와 노출되지 않은 가구 간의 매출 차이를 조사함으로써 수천 개의 캠페인에서 생성된 매출 상승을 매우 정확하게 계산할 수 있습니다*.
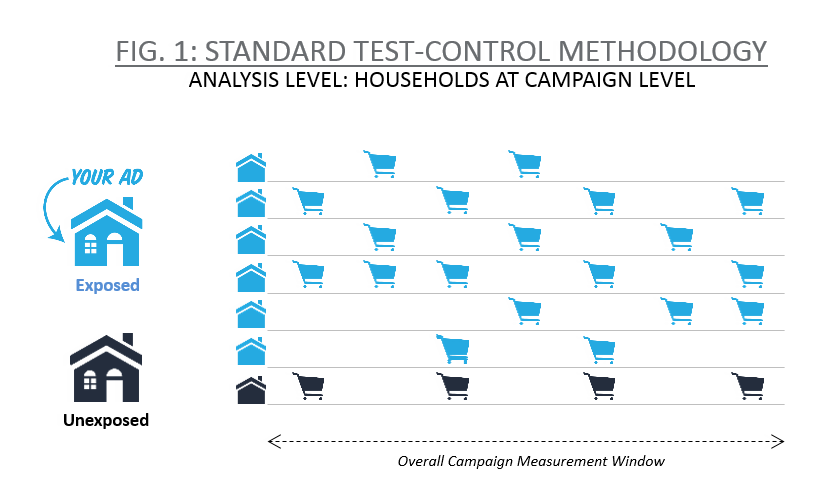
이 테스트 및 제어 방법론의 기초가 되는 공분산 분석(ANCOVA) 모델은 철저한 검증을 거쳤으며, 캠페인 전반의 효과를 측정하고자 하는 브랜드 관리자에게 빠르고 신뢰할 수 있는 답변을 제공합니다. 하지만 이 방법이 적합하지 않은 경우도 있습니다. 예를 들어, 캠페인에 노출되지 않은 가구를 찾기가 거의 불가능할 정도로 많은 오디언스에게 도달한 캠페인의 경우를 생각해 보겠습니다(그림 1 참조). 대조군은 어디서 찾을 수 있을까요?
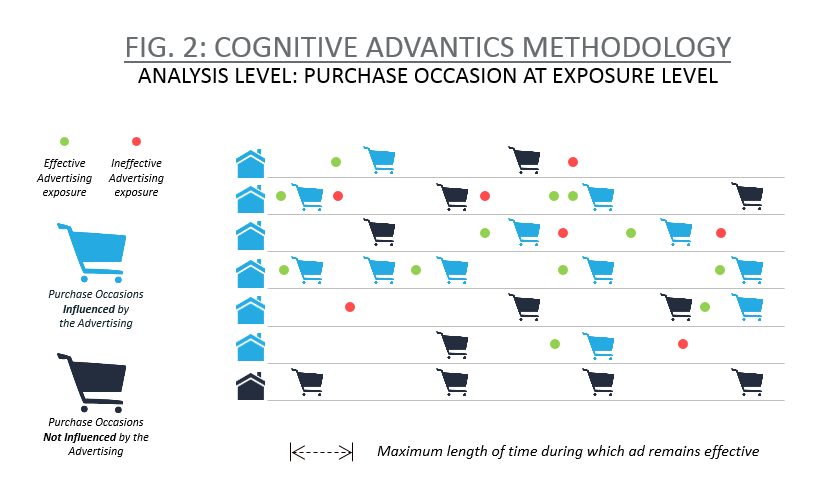
이러한 문제를 해결하기 위해 크리테오는 '인지적 이점(CA)'이라는 새로운 방법론을 개발했습니다. 전체 광고 캠페인 기간 동안의 매출 상승을 총체적으로 조사하는 대신, 각 구매 기회 수준에서 가구별 매출 데이터를 분석하고 광고 노출 타이밍을 고려하여 데이터를 훨씬 더 세밀하게 살펴볼 수 있습니다. 결국, 한 가구가 광고를 보고 구매를 한 후 같은 브랜드의 광고를 다시 볼 수 있는데, 두 번째 광고가 특정 구매에 영향을 미쳤다고 말하기는 어렵습니다. 반대로 한 가구가 광고를 보고 두 달 후에 구매할 수 있는데, 그 사이에 많은 시간이 지났기 때문에 광고 노출이 구매를 결정했다고 단정하기는 어렵습니다.
구매 기회 수준에서 데이터를 분석하면 노출의 '최근성'을 고려할 수 있으며, 광고가 최근일수록 더 큰 영향을 미칩니다. 유효 기간은 연구마다 다를 수 있지만, 일반적으로 구매 시점으로부터 28일을 기준으로 구매 시점의 원인이 될 수 있는 하나 이상의 노출을 찾습니다(그림 2 참조). 또한 캠페인에 한 번도 노출되지 않은 가구가 많지는 않지만, 노출된 가구 중에서도 일반적으로 구매 직전에 광고의 영향을 받지 않은 구매 기회가 충분히 존재하기 때문에 대조군 문제를 해결할 수 있습니다.
분석을 수행하기 위해 CA 방법론은 모든 관련 변수(구매 내역, 미디어 소비, 인구 통계, 위치, 카테고리 구매 등)를 가져와 데이터 모델링 알고리즘 모음에 공급하고, 데이터가 모델을 선택하고 결합하여 최상의(즉, 가장 통계적으로 건전한) 교차 검증 결과를 얻을 수 있도록 합니다. 이것이 바로 CA 이름에서 '인지' 부분입니다. 최종 결과는 사람의 개입에 거의 의존하지 않고 대규모로 배포할 수 있는 매우 강력한 도구입니다.
시장이 실시간 푸시 버튼 솔루션으로 이동함에 따라, 이는 광고 효과 측정의 다음 단계로 진화하고 있습니다. 초기 결과는 매우 유망하며, 향후 발행될 저널에서 자세한 내용과 사례, 성과 벤치마크를 공유할 수 있기를 기대합니다.
*이 방법에 대한 자세한 내용은 다음을 참조하세요: 닐슨 측정 저널 1권 2호에서 단일 소스 데이터를 사용하여 광고 효과 측정하기.



