Manfaat dari kemajuan teknologi tampaknya tidak ada habisnya. Kita dapat memeriksa keamanan rumah kita dari ponsel kita, menerima pengiriman barang belanjaan dengan drone-bahkan mengemudikan mobil yang dapat memarkir secara paralel untuk kita. TV kita juga semakin canggih, menawarkan pilihan konten yang tampaknya tak ada habisnya di berbagai platform dan saluran yang terus berkembang. Namun, terlepas dari banyaknya pintu yang akan dibuka oleh TV pintar di tahun-tahun mendatang, mereka tidak akan - dengan sendirinya - dapat memberikan pandangan akurat kepada industri media tentang siapa yang menggunakannya.
Smart TV telah mengambil alih lorong TV di toko-toko besar setempat. Anda akan kesulitan menemukan TV di toko saat ini yang tidak memiliki koneksi internet. Dan seperti halnya semua perangkat yang terhubung, TV pintar menambah jumlah data yang dihasilkan pengguna: Data pengenalan konten otomatis (ACR) adalah teknologi yang digunakan OEM untuk menangkap penyetelan pada TV pintar. Ketika digabungkan dengan informasi yang merinci perilaku yang representatif, perilaku tingkat orang, kumpulan data ini secara signifikan memajukan ilmu pengetahuan tentang pengukuran pemirsa.
Mengingat adopsi yang luas dari smart TV dan data yang mereka hasilkan, tidak mengherankan jika sejumlah perusahaan melihat data ACR sebagai cara untuk mengukur pemirsa. Dari perspektif skala, peluang ini sangat menarik. Namun, sumber data yang menguntungkan seperti ACR tidaklah cukup untuk mengukur audiens, hanya karena ACR tidak memiliki aspek yang paling penting dalam pengukuran audiens: orang. Selain tidak representatif-ataubahkan tidak mengetahui apakah seseorang benar-benar menonton apa yang ada di layar-data ACR memiliki kelemahan validasi yang kritis: Data ini mengharuskan produsen perangkat untuk mencocokkan gambar di layar dengan gambar referensi untuk menentukan konten apa yang ditampilkan. Jadi, cara terbaik untuk membuka potensi data ACR yang sebenarnya adalah dengan mengkalibrasi data tersebut dengan data yang mencerminkan perilaku menonton yang sebenarnya.
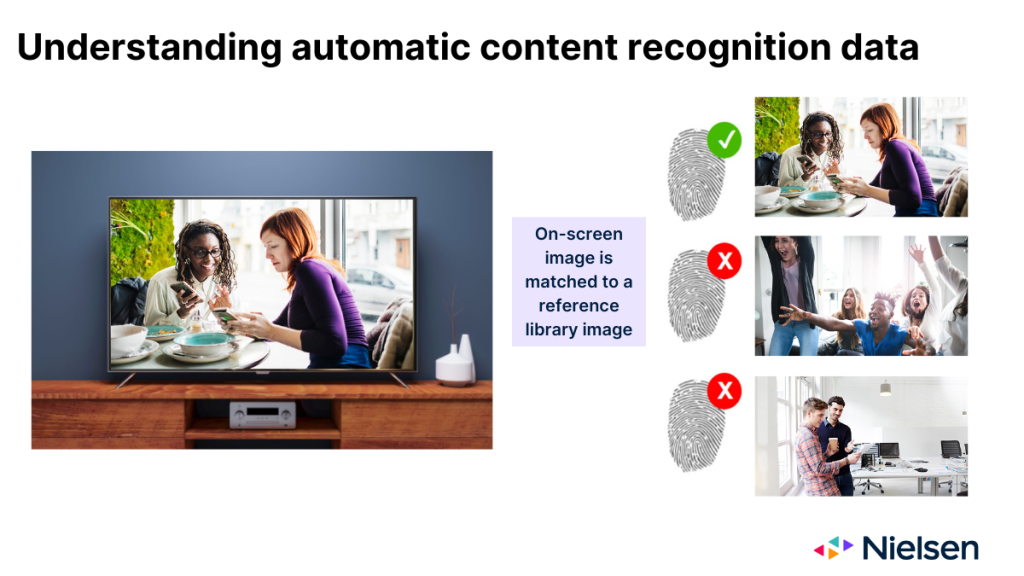
Ketika bekerja sesuai rancangan, teknologi ACR memantau gambar yang diproyeksikan pada kaca TV, dan menggunakan gambar tersebut untuk menyimpulkan konten apa yang sedang ditampilkan. Gambar yang disajikan ACR bertindak dalam banyak hal seperti sidik jari konten. Namun setelah mengumpulkan "sidik jari", teknologi ini perlu menentukan jaringan atau platform mana yang menampilkan gambar tersebut, serta kapan gambar itu muncul. Untuk menentukan hal tersebut, teknologi perlu mencocokkan gambar di layar dengan gambar yang terdapat dalam pustaka referensi yang dikelola oleh produsen.
Ada tiga hasil yang mungkin terjadi ketika teknologi mencoba membuat kecocokan itu:
- Gambar cocok dengan satu entri dalam pustaka referensi
- Gambar cocok dengan beberapa entri dalam pustaka referensi
- Gambar yang cocok tidak ada dalam pustaka referensi
Bagi semua pihak yang terlibat, hasil pertama adalah skenario yang ideal. Skenario kedua kurang ideal, dan memiliki beberapa tingkat risiko salah kredit, hanya karena berbagai alasan untuk beberapa pertandingan (misalnya, penayangan di seluruh jaringan, pengulangan penayangan, siaran ulang). Pada skenario ketiga, tidak ada yang mendapatkan kredit, yang jelas merupakan skenario yang paling tidak diinginkan. Alasan paling umum untuk hasil ini adalah karena konten ditayangkan di jaringan yang tidak dipantau oleh OEM.
Bahkan jika pencocokan gambar adalah solusi pengukuran yang berdiri sendiri, kemampuan untuk memanfaatkannya tidak akan pernah bisa dilakukan. Seperti yang bisa Anda bayangkan, biaya untuk memelihara perpustakaan setiap frame dari setiap acara di televisi bukanlah tugas yang kecil. Ini juga merupakan tugas yang akan terus bertambah secara eksponensial. Juga tidak ada periode penyimpanan standar untuk gambar.
Jadi, bagaimana kita tahu bahwa teknologi ACR akan menjadi pasangan yang tepat? Tanpa mekanisme yang dapat mengisi kekosongan, kami tidak akan tahu. Itulah mengapa Nielsen telah berinvestasi dalam tanda air, yang jauh lebih deterministik daripada tanda tangan, serta cadangan tanda tangan untuk setiap umpan yang diukur. Hal ini memberikan representasi dari semua konten-mengisi kesenjangan yang terkait dengan big data dengan sendirinya. Dengan terisinya kesenjangan ini, data besar yang berasal dari sumber seperti ACR memberikan manfaat skala dalam lanskap media yang semakin tersegmentasi. Dan ketika kita menggunakan kontrol pembobotan untuk mengkalibrasi data besar dengan data penayangan tingkat orang, kita dapat melihat titik perbandingan yang seharusnya kosong.
Dalam sebuah studi baru-baru ini, Nielsen berusaha memahami sejauh mana kesenjangan pustaka referensi ini memengaruhi log tuning ACR-dasar pengukuran berbasis ACR. Dalam analisis rumah umum bulan September 2021, kami menganalisis data dari dua mitra penyedia ACR kami untuk memahami di mana kesenjangan pustaka referensi dapat mempengaruhi pengukuran. Dalam penelitian kami, kami melihat konsentrasi sumber penayangan dan menit yang ditonton dari sumber yang tersedia.
Di seluruh sumber penayangan, kami menemukan bahwa mitra penyedia ACR kami hanya memantau 31% stasiun yang tersedia. Itu berarti mereka tidak menyimpan data di perpustakaan referensi mereka untuk 69% stasiun. Ketika kami melihat menit yang dilihat, kami menemukan bahwa 23% menit berasal dari stasiun yang tidak dipantau. Ini berarti perusahaan yang memanfaatkan data ACR saja untuk pengukuran akan mengurangi tayangan tingkat rumah tangga sebesar 23%.
Terlepas dari keterbatasan data ACR itu sendiri, kami memahami peluang skala dan jangkauan yang disediakannya sebagai sumber cakupan tambahan - mirip dengan data jalur balik (RPD) dari dekoder, yang juga dikalibrasi oleh strategi data besar kami dengan data panel untuk mengatasi keterbatasan yang sebanding. Dengan mengintegrasikan kumpulan data besar dengan data penayangan kami, yang memberikan pengukuran yang representatif untuk total AS, kami dapat meningkatkan ukuran sampel kami secara signifikan sembari menerapkan metodologi ilmu data yang ketat untuk mengisi kesenjangan dan memastikan representasi yang adil dari total pemirsa AS di semua jaringan dan platform.
Versi artikel ini pertama kali muncul di AdExchanger.