Los beneficios del avance tecnológico parecen no tener fin. Podemos controlar la seguridad de nuestras casas desde el teléfono, recibir entregas de comestibles por dron e incluso conducir coches que aparcan en paralelo por nosotros. Nuestros televisores son cada vez más avanzados y ofrecen un sinfín de opciones de contenido en un panorama cada vez más amplio de plataformas y canales. Sin embargo, a pesar de las muchas puertas que abrirán los televisores inteligentes en los próximos años, no serán capaces por sí solos de proporcionar al sector de los medios de comunicación una visión precisa de quién los utiliza.
Los televisores inteligentes se han apoderado de la sección de televisores de las grandes superficies. Hoy en día, es difícil encontrar en una tienda un televisor que no esté conectado a Internet. Y al igual que todos los dispositivos conectados, los televisores inteligentes se suman a la creciente proliferación de datos generados por los usuarios: Los datos de reconocimiento automático de contenidos (ACR) son la tecnología que utilizan los fabricantes de equipos originales para capturar la sintonización en los televisores inteligentes. Cuando se combinan con información que detalla el comportamiento representativo a nivel de persona, estos conjuntos de datos hacen avanzar significativamente la ciencia de la medición de audiencias.
Dada la amplia adopción de televisores inteligentes y los datos que producen, no es de extrañar que una serie de empresas estén buscando en los datos de ACR una forma de medir las audiencias. Desde el punto de vista de la escala, la oportunidad es muy atractiva. Sin embargo, por muy lucrativa que sea la fuente de datos ACR, no basta por sí sola para medir audiencias, sencillamente porque carece del aspecto más importante que existe en la medición de audiencias: las personas. Además de no ser representativos -nisiquiera conscientes de si alguien está viendo realmente lo que hay en la pantalla-, los datos de ACR tienen un fallo de validación crítico: requieren que el fabricante del dispositivo compare la imagen de la pantalla con una imagen de referencia para determinar qué contenido se está mostrando. Por tanto, la mejor forma de liberar el verdadero potencial de los datos ACR es calibrarlos con datos que reflejen el verdadero comportamiento de visualización de las personas.
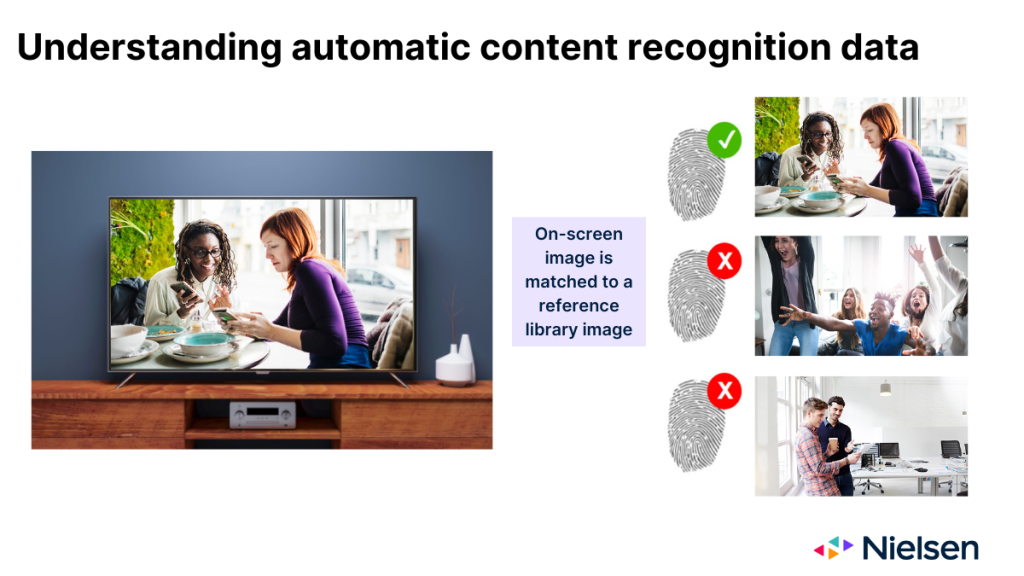
Cuando funciona según lo previsto, la tecnología ACR supervisa las imágenes que se proyectan en el cristal del televisor y las utiliza para deducir qué contenido se está mostrando. Las imágenes que sirve ACR actúan en muchos sentidos como una huella dactilar del contenido. Pero después de recoger las "huellas dactilares", la tecnología necesita determinar en qué red o plataforma apareció la imagen, así como cuándo apareció. Para ello, la tecnología debe comparar la imagen de la pantalla con una imagen contenida en una biblioteca de referencia mantenida por el fabricante.
Hay tres resultados posibles cuando la tecnología intenta hacer esa coincidencia:
- La imagen coincide con una única entrada de la biblioteca de referencia
- La imagen coincide con varias entradas de la biblioteca de referencia
- No hay ninguna imagen coincidente en la biblioteca de referencia
Para todas las partes implicadas, el primer resultado es el ideal. El segundo escenario es menos ideal, y conlleva cierto nivel de riesgo de error de acreditación, simplemente debido a las diversas razones de los partidos múltiples (por ejemplo, emisiones a través de redes, repeticiones de emisiones, simulcasts). En el tercer escenario, nadie obtiene créditos, que es obviamente el escenario menos deseable. La razón más común de este resultado es que el contenido se emitió en una red que el OEM no supervisa.
Incluso si la correspondencia de imágenes fuera una solución de medición independiente viable, la capacidad de aprovecharla como tal nunca sería factible. Como puede imaginarse, el coste de mantener una biblioteca de todos y cada uno de los fotogramas de cada acontecimiento televisivo no es tarea fácil. También es una tarea que crecerá exponencialmente a perpetuidad. Tampoco existen periodos de conservación estándar para las imágenes.
Entonces, ¿cómo sabemos que la tecnología ACR acertará? Sin un mecanismo que pueda rellenar los espacios en blanco, no lo sabemos. Por este motivo, Nielsen ha invertido en marcas de agua, que son mucho más deterministas que las firmas, así como en copias de seguridad de las firmas para cada fuente medida. Esto proporciona una representación de todo el contenido, rellenando los huecos asociados al big data por sí mismo. Una vez cubiertas estas lagunas, los macrodatos procedentes de fuentes como ACR ofrecen la ventaja de la escala en un panorama mediático cada vez más segmentado. Y cuando utilizamos controles de ponderación para calibrar los big data con los datos de visionado a nivel de persona, podemos ver puntos de comparación que de otro modo estarían en blanco.
En un estudio reciente, Nielsen trató de entender hasta qué punto estas lagunas en las bibliotecas de referencia afectan a los registros de sintonización ACR, la base de la medición basada en ACR. En un análisis de hogares comunes realizado en septiembre de 2021, analizamos los datos de nuestros dos socios proveedores de ACR para comprender dónde podrían influir las lagunas de las bibliotecas de referencia en la medición. En nuestro estudio, nos fijamos tanto en la concentración de fuentes de visionado como en los minutos vistos de las fuentes disponibles.
Entre todas las fuentes de visionado, descubrimos que nuestros socios proveedores de ACR supervisan sólo el 31% de las emisoras disponibles. Esto significa que no mantienen datos en sus bibliotecas de referencia para el 69% de las emisoras. Cuando nos fijamos en los minutos vistos, descubrimos que el 23% de los minutos procedían de emisoras no supervisadas. Esto significa que las empresas que sólo utilizan los datos de ACR para la medición estarían subestimando las impresiones a nivel doméstico en un 23%.
A pesar de las limitaciones de los datos de ACR por sí solos, entendemos la oportunidad de escala y alcance que proporcionan como fuente adicional de cobertura, similar a la de los datos de trayectoria de retorno (RPD) de los descodificadores, que nuestra estrategia de big data también calibra con datos de panel para abordar limitaciones comparables. Al integrar los conjuntos de big data con nuestros datos de audiencia, que proporcionan una medición representativa del total de los EE.UU., podemos aumentar significativamente el tamaño de nuestras muestras al tiempo que aplicamos metodologías rigurosas de ciencia de datos para llenar los vacíos y garantizar una representación justa de la audiencia total de los EE.UU. en todas las redes y plataformas.
Una versión de este artículo apareció originalmente en AdExchanger.