技术进步带来的好处似乎无穷无尽。我们可以通过手机查看家中的安全状况,接收无人机送货上门的杂货,甚至驾驶可以为我们并排停车的汽车。我们的电视机也变得同样先进,在不断增长的平台和频道中提供看似无穷无尽的内容选择。然而,尽管智能电视在未来几年将打开许多大门,但它们本身并不能让媒体行业准确了解谁在使用智能电视。
智能电视已经占据了当地大卖场的电视货架。如今,你很难在商店里找到一台不支持互联网的电视机。就像所有联网设备一样,智能电视使用户生成的数据日益激增:自动内容识别(ACR)数据是原始设备制造商用来捕捉智能电视调谐的技术。这些数据集与详细描述具有代表性的个人行为的信息相结合,极大地推动了受众测量科学的发展。
鉴于智能电视的广泛应用及其产生的数据,一系列公司将 ACR 数据作为衡量受众的一种方法也就不足为奇了。从纯粹的规模角度来看,这个机会非常有吸引力。然而,尽管 ACR 是一个利润丰厚的数据源,但它本身并不足以衡量受众,原因很简单,因为它缺乏受众衡量中最重要的方面:人。除了 不具有代表性,甚至不知道是否有人真正在观看屏幕上的内容外,ACR 数据还有一个关键的验证缺陷:它要求设备制造商将屏幕上的图像与参考图像进行匹配,以确定显示的是什么内容。因此,发掘 ACR 数据真正潜力的最佳方法是用反映真实个人观看行为的数据对其进行校准。
在按设计工作时,ACR 技术会监控投射到电视玻璃上的图像,并利用这些图像来推断正在显示的内容。ACR 提供的图像在很多方面就像内容的指纹。但在收集 "指纹 "后,该技术需要确定图像出现在哪个网络或平台上,以及出现的时间。为了进行判断,该技术需要将屏幕上的图像与制造商维护的参考库中的图像进行匹配。
当技术尝试进行匹配时,有三种可能的结果:
- 该图像与参考文献库中的一个条目相匹配
- 图像与参考资料库中的多个条目相匹配
- 参考资料库中没有匹配的图像
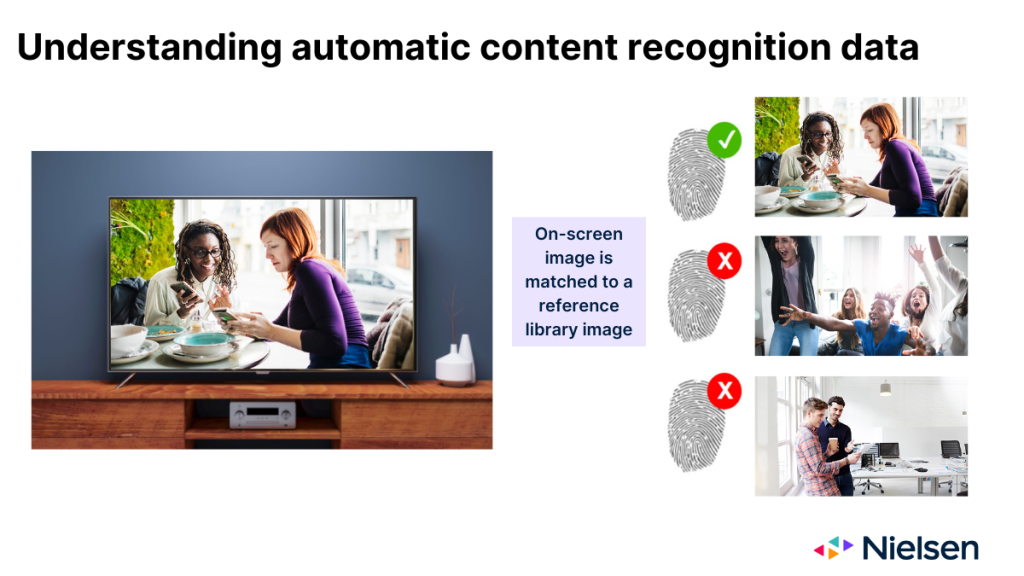
对所有相关方而言,第一种结果是最理想的情况。第二种情况就不那么理想了,它存在一定程度的错误记分风险,原因很简单,因为多场比赛有多种原因(如跨网播出、重复播出、同步播出)。在第三种情况下,没有人获得记分,这显然是最不理想的情况。造成这种结果的最常见原因是,内容在原始设备制造商没有监控的网络上播出。
即使图像匹配是一种可行的独立测量解决方案,也不可能将其作为一种可行的解决方案加以利用。可以想象,要维护一个包含电视上每一个事件的每一帧画面的资料库,所需的成本并不低。这也是一项将永久呈指数增长的任务。图像也没有标准的保存期限。
那么,我们如何知道 ACR 技术能够进行正确的匹配呢?如果没有能够填补空白的机制,我们就不知道。这就是尼尔森投资水印的原因,水印的确定性远高于签名,同时尼尔森还为每个测量数据源提供签名备份。这提供了所有内容的代表性,填补了与大数据本身相关的空白。填补了这些空白后,来自 ACR 等来源的大数据就能在日益细分的媒体环境中提供规模优势。当我们使用加权控制将大数据与个人层面的收视数据进行校准时,我们就能看到原本空白的比较点。
在最近的一项研究中,尼尔森希望了解这些参考资料库差距对 ACR 调谐日志(基于 ACR 的测量基础)的影响程度。在 2021 年 9 月的共同家园分析中,我们分析了来自两个 ACR 提供商合作伙伴的数据,以了解参考资料库差距在哪些方面可能会影响测量结果。在我们的研究中,我们同时考察了收视源的集中度和可用收视源的收视分钟数。
在所有收视来源中,我们发现 ACR 提供商合作伙伴仅监控了 31% 的可用电台。这意味着他们的参考库中没有保存 69% 的电台数据。当我们查看观看的分钟数时,我们发现 23% 的分钟数来自未受监控的电视台。这意味着,仅利用 ACR 数据进行测量的公司会少计 23% 的家庭级印象。
尽管 ACR 数据本身存在局限性,但我们深知其作为额外覆盖来源所提供的规模和覆盖范围的机会--类似于来自机顶盒的返回路径数据 (RPD),我们的大数据战略也将其与面板数据进行校准,以解决类似的局限性。通过将大数据集与我们的收视数据(可提供具有代表性的全美测量数据)相整合,我们能够大幅增加样本量,同时应用严格的数据科学方法来填补空白,确保公平地代表所有网络和平台上的全美受众。
本文最初出现在 AdExchanger 上。